Roads Of Thought
21 Mar 2022 - Ryan Llamas
“Language is the most massive and inclusive art we know, a mountainous and anonymous work of unconscious generations.” — Edward Sapir
The Foundation I Take Notes From
As I was reading Foundations of Statistical Natural Language Processing, I couldn’t help but stop to look up each individual who made a major contribution to the field of NLP. Learning about these individuals and understanding their givings to the field taught me much about how our current NLP algorithms and structures came to fruition.
For example, learning about Ludwig Wittgenstein’s idea of the use of a word in everyday life playing a role in language. Or Edward Sapir’s contributions to the study of Native American language, finding how cultural patterns shape a society and its language. It is all too fascinating to ignore!

Above is Ludwig Wittgenstein, Edward Sapir, and Noam Chomskey
At the beginning of the book, the main person it likes to point out is Noam Chomsky and his ideas. He contributed to NLP by creating a method to say whether a sentence is a “grammatical” or an “ungrammatical” one using a defined rule set purposed for the English language. He also believed everyone internally has a common set of rules for language and goes about proving these ideas showing how similar different languages are.
Funny enough, the book seems to argue against these ideas and models when it comes to crafting meaningful sentences and building practical applications. After all, it makes sense for a book focused on the statistics of NLP rather than the groupings of words and their pairings. It begs for opinionated structure and meaning, and Noam Chomskey offers quite the opposite.
The points presented are fair when it comes to making sentences of note rather than ambiguity. For example, Noam Chomsky believes the sentence “Colorless green ideas sleep furiously” is a grammatically correct sentence, but in truth, doesn’t seem practical in reality. With this, we travel into the approaches a NLP researcher takes.
Two Roads of Thought
The book argues there are two roads of thought when approaching a NLP problem. One approach is the Rationalist approach, where certain knowledge of a language’s structure is innate, even coining the term people have an innate language faculty. Noam Chomsky is a strong supporter of this approach, stating if an advanced alien martian were to arrive at earth, he would deduce there is only one language with local variants depending on where you are.
Then there is the Empiricist approach, the method of applying a language model/structure and then analyzing it with statistical methods to influence its output. This approach does not support the idea that there is an declared set of rules in language, but language itself adapts based on its present use.
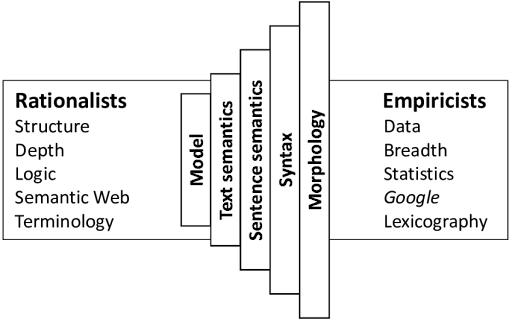
You can see how Chomskey’s ideas sponsor the categorical approach of saying there are grammatical and ungrammatical sentences due to the declared definitive structure rationalists apply to language. However, Empiricists do not accept the notion of whether a sentence is grammatical, but that its use is clearly expressed in a meaningful way.
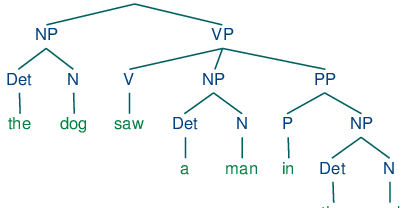
For example, take a look at a Rationalist approach for crafting grammatical sentences. The below diagram used a Context Free Grammar approach (CFG for short) to craft grammatical sentences. Using a set of lexical rules, it defines what types of words go with its Part of Speech (POS), such as a “Determiner” with a “Noun” is considered a “NP”. You can see how static this makes sentence generation and how it can end up making cryptic sentences. We will dig into this more later…
What is Widely Accepted Nowadays?
I believe this is a matter of opinion, as no clear answer could be produced after looking into this delicate question. The Empirest approach declares the answer is in the data while the Rationalist approach says the answer is universally defined in nature. But my belief is there are not only two practical approaches, and one should explore the possibility of combining these approaches to produce more fantastic methods and results for future NLP problems.
To look into this question, I was heavily influenced by Kenneth Church and Mark Liberman’s latest paper The Future of Computational Linguistics: On Beyond Alchemy. The paper points out other approaches such as Associationism (the frequency of X and Y will influence the use of X and Y more in the future) and Connectionism (the modeling of neural networks to produce intellectual responses) and points out how approaches rise and fall based on the latest discoveries/leaders in the industry. If one were to see the connections that could be drawn between these approaches, I truly believe there are hidden developments just waiting to be discovered.
They also reinforce the idea that young researchers who rebel against the precedent to find new practices are the future for the industry, but recognize the risks associated with it can lead to pure rejection and wasted time. I feel the risk is worth the benefit, as NLP solutions are becoming more and more involved such as achievements like Amazon’s Alexa. It is why I am so bold to say there must be more than meets the eye.
Context Free Grammar Challenge
To show the power of CFGs, I decided to make one using a set of sentences. To further challenge myself, I wanted to make it into the Chomsky Normal Form considering we brought up Noam Chomsky’s idea of a “grammatical” sentence. A grammar is considered in Chomsky Normal Form if it follows a certain set of rules:
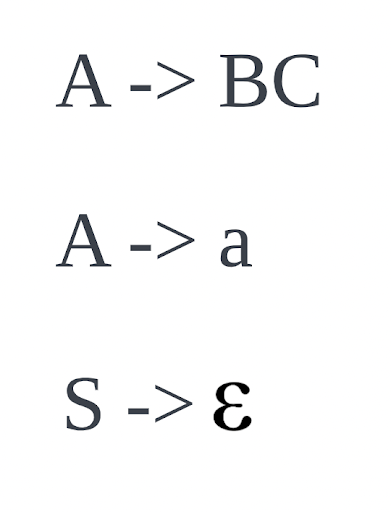
What do these symbols mean? Great question, let’s break it down. Every grammar must have a starting point to generate a sentence. This is what “S” is, our Starting Point. “S” will need to know its options for generating a sentence, so it is made up of Nonterminals, aka “A” and “B”. The rule “A->BC” is called a Production, defining what a nonterminal is able to produce using other nonterminals. Then there is “a” which is considered a terminal. Terminals in our case are the words we will use in a sentence. For example, the word “the” is considered a terminal. The epsilon symbol refers to the fact that S (and only S) can produce an empty string if it chooses. As long as your grammar satisfies these rules, it is considered in Chomsky Normal Form.
So why are CFGs so powerful and what does having it in Chomsky Normal Form achieve? A CFG without the rule set of Chomsky Normal Form can be powerful alone as it can parse and map a set of terminals for computation purposes. Consider the equation (2+3)+5: knowing the answer is ten is simple for the human mind, but for a machine, a CFG is essential. This allows the analysis of PEMDAS operation rules for more complex equations. See how this maps in a CFG:
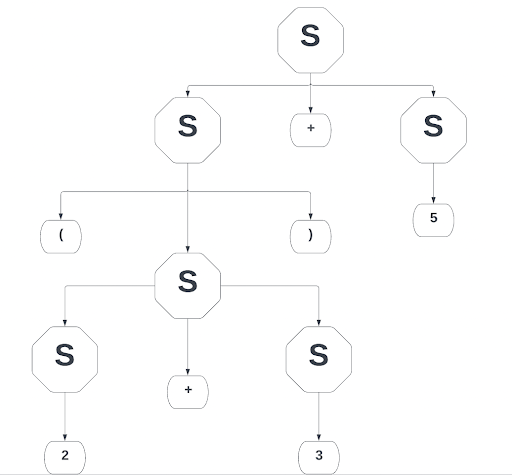
Note that given a more complex equation, a CFG could be mapped in many different ways. The same thing goes for language as well.
Now what makes Chomsky Normal Form so attractive when making your CFG? It is due to: its simplistic set of rules to be met, attractive existing algorithms such as CYK to identify if a sentence can be made into Chomsky Normal Form in a reasonable time, and the multitude of proofs and analysis made with the given rule set. For example, let’s say we have the sentence “Welcome to my home.” I can identify that I have five values/terminals in this sentence (including the period) and can say if I had a CFG that parsed this sentence in Chomsky Normal Form, I would end up with 9 production rules (A->BC). Later on, you will see how I came to this conclusion, but this is one of the few examples on how CFGs are useful in defining computation expectations.
Now, to add some humor to the problem and solution. Considering CFGs often create sentences that provide little meaning or seem metaphorical in nature, I decided to use sentences only Yoda from Star Wars would use. It seems appropriate considering if you were to try to understand a sentence produced by a CFG, it would come off as a riddle. Hence, I will try to craft a yoda text generator using a CFG in Chomsky Normal Form.

“He once said to me, “Size matters not.” That’s how he talked. He would speak in riddles.” - Luke Skywalker
Coding Solution
I decided to solve this problem in Python using the NLTK package, a popular package for NLP solutions. First, we will need data to analyze and feed to our CFG. Scouring the internet, I found an array on github of Yoda sentences to use, and added additional ones to cover some edge cases:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
quotes = [
"No different I.",
"Yes, No different I.",
"Agree with you, the council does.",
"Your apprentice, Skywalker will be.",
"Always two there are, no more, no less: a master and an apprentice.",
"Fear is the path to the Dark Side.",
"Fear leads to anger, anger leads to hate; hate leads to suffering.",
"I sense much fear in you.",
"Qui-Gon's defiance I sense in you.",
"Truly wonderful the mind of a child is.",
"Around the survivors a perimeter create.",
"Lost a planet Master Obi-Wan has.",
"How embarrassing...How embarrassing.",
"Victory, you say?",
"Master Obi-Wan, not victory.",
"The shroud of the Dark Side has fallen.",
"Begun the Clone War has.",
"Much to learn you still have... my old padawan... this is just the beginning!",
"Twisted by the Dark Side young Skywalker has become.",
"The boy you trained, gone he is, consumed by Darth Vader.",
"The fear of loss is a path to the Dark Side.",
"If into the security recordings you go, only pain will you find.",
"Not if anything to say about it I have.",
"Great warrior, hmm?",
"Wars not make one great.",
"Do or do not; there is no try.",
"Size matters not.",
"Look at me.",
"Judge me by my size, do you?",
"That is why you fail.",
"No!",
"No similar.",
"You must unlearn what you have learned.",
"Only different in your mind.",
"Always in motion the future is.",
"Reckless he is.",
"Matters are worse.",
"When nine hundred years old you reach, look as good, you will not.",
"No.",
"There is... another... Sky... walker..."
]
One of the few challenges of generating a CFG with a random set of sentences is:
- Making sure to keep track of all its components, in this case, its nonterminals, productions, and starting points
- Defining a Algorithm to parse a sentence and create new unique productions
- Ensuring you have a way to parse a sentence and end up with the same “S”
While there are algorithms to modify an existing CFG to Chomsky Normal Form, it gets more complicated to generate a CFG from the ground up while ensuring it meets its rules and satisfies all previous sentences. After googling and realizing there is no defined algorithm for this task, I decided to create my own. It follows four steps: Find the POS of a sentence, see if it covers existing production rules and “mutate” it, parse the “mutated” sentence with newly created production rules, and rinse and repeat. Lets see this pattern in code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
posInSentence = []
overallStartingNonTerminals = []
overallStartingAndLeafNonTerminals = [] # Step 1
overallProductionsFound = []
rollingID = 0
for sentence in quotes:
print("-------Start of Algorithm-------")
posInSentence = getPOSOfSentence(sentence) # Step 2
unfoundProductionsForNonTerminals = mutateListWithAlreadyDeclaredProductions(posInSentence) # Step 3
print("Displaying unfound nonterminals after mutation process: " + unfoundProductionsForNonTerminals.__str__())
determineNonterminalsThatIsChildAndStart(unfoundProductionsForNonTerminals) # Step 4
performRightToLeftProductionCreation(unfoundProductionsForNonTerminals) # Step 5
posInSentence.clear() # Step 6
print("Our new starting nonterminals: " + overallStartingNonTerminals.__str__())
print("Starting and Leaf nonterminals: " + overallStartingAndLeafNonTerminals.__str__())
print("Overall productions found thus far: " + overallProductionsFound.__str__())
print("-------End of Algorithm-------")
- I keep track of five things in the overall program. Will go into detail for each later
- Method that returns the Part of Speech(POS) for a sentence
- Method that modifies POS with existing productions (My “Mutation”)
- Method that determines if a S was also found as a leaf of a sentence
- Parses the POS with possible mutations and creates new production rules with a new “S”
- Clears the POS for the sentence and starts again
Finding this method of approach required some research into existing algorithms to see what I could modify to fit my use case. I used a combination of steps as reference from converting CFG to Chomsky Normal Form algorithm to CYK algorithm. I even performed it by hand for a few sentences to ensure it was a feasible approach.
However, it looks simple from this viewpoint, so let’s take a closer look at each method, starting with how I get the POS:
1
2
3
4
5
6
7
8
9
10
11
12
def getPOSOfSentence(sentence):
global overallProductionsFound
print("Sentence: " + sentence) # Step 1
temp = []
for word_and_pos in nltk.pos_tag(word_tokenize(sentence)): # Step 2
temp.append(Nonterminal(word_and_pos[1])) # Step 3
newTerminal = Production(Nonterminal(word_and_pos[1]), [word_and_pos[0]]) # Step 4
if overallProductionsFound.count(newTerminal) == 0: # Step 5
overallProductionsFound.append(newTerminal)
print("All POS found in sentence: " + temp.__str__())
return temp
- I track overallProductionsFound and the sentences POS in temp
- for loop that iterates on each word in the sentence getting its POS
- Append the POS for the word in temp
- Create a Production that maps to a terminal, in this case the POS being its nonterminal
- Will add the Production rule only if it does not already exist in overallProductionsFound
You can see how this method begins to add our initial production rules. In this case, it satisfies the condition “A -> a” if we were to look back on Chomsky Normal Form’s conditions. Lets see how this prints in terminal for one sentence:
-------Start of Algorithm-------
Sentence: No different I.
All POS found in sentence: [DT, JJ, PRP, .]NLTK is doing its job well providing us the POS for each word in the sentence. In this case:
- “The” maps to “DT” which translates as a determiner
- “Different” maps to “JJ” which translates as a adjective
- “I” maps to “PRP” which translates as a personal pronoun
- Finally, the period
This is NLTK at work, with tools like word_tokenize() to split the sentence in an array of words/punctuation and pos_tag() to determine the POS for each word in the array. We also see the first use of classes Nonterminal and Production, as a production is mapped out as A->a or DT->”the”.
Now that we have our POS for the sentence and the initial production rules, we can start parsing this array and create our production rules satisfying the condition A -> BC. However, we wouldn’t want to create duplicate productions while parsing this array. Hence, we will now mutate this array to match with existing production rules:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def mutateListWithAlreadyDeclaredProductions(initalNonTerminals):
global overallProductionsFound # Step 1
foundExistingProduction = False
if overallProductionsFound.__len__() != 0: # Step 2
index = len(initalNonTerminals) - 1
while index > 0: # Step 3
lhs = initalNonTerminals.__getitem__(index - 1) # Step 4
rhs = initalNonTerminals.__getitem__(index)
for production in overallProductionsFound:
if production.rhs().__eq__((lhs, rhs)): # Step 5
initalNonTerminals.pop(index)
initalNonTerminals.pop(index - 1) # Step 6
initalNonTerminals.insert(index-1, production.lhs())
foundExistingProduction = True # Step 7
break
index -= 2 # Step 8
if index == 0:
lhs = initalNonTerminals.__getitem__(index)
rhs = initalNonTerminals.__getitem__(index+1)
for production in overallProductionsFound:
if production.rhs().__eq__((lhs, rhs)): # Step 9
initalNonTerminals.pop(0)
initalNonTerminals.pop(0)
initalNonTerminals.insert(0, production.lhs())
foundExistingProduction = True
break
if (foundExistingProduction == True):
mutateListWithAlreadyDeclaredProductions(initalNonTerminals) # Step 10
return initalNonTerminals
- I keep track if I foundExistingProductions while parsing
- A conditional to find out if we have production rules defined
- Loop until the index is at the last element of initialNonTerminals
- Define what is the lhs (Left Hand Side) and rhs (Right Hand Side) of the current index
- Loop through every production rule to check if its production.rhs() is equal to the nonterminals we defined in step 4
- If we found a match: remove both nonterminals with pop() and replace it with production.lhs()
- Mark that we have found an existing production rule with foundExistingProduction. Also break out of loop because a found production rule
- Move the index over two in index-=2
- This step is very similar to steps 7 and 8, only difference is we define the lhs and rhs differently to not go over index bound
- If foundExistingProduction is true, then perform a recursion until we find no existing production rules
This parsing algorithm was actually defined after I made the algorithm for performRightToLeftProductionCreation(). I realized after its creation that I needed to find a way to modify sentences with existing rules to avoid recreating productions. I also found that if I have a sentence T and a start S: if S->T, then I should have a way to map T->S.
Hence, mutateListWithAlreadyDeclaredProductions() was made to satisfy this need. Consider the sentence “Agree with you, the council does.” Let’s say I had the array with two copies of this sentence. I should expect this sentence to map back to the same S. Lets see this in action:
-------Start of Algorithm-------
Sentence: Agree with you, the council does.
All POS found in sentence: [VB, IN, PRP, ,, DT, NN, VBZ, .]
Displaying unfound nonterminals after mutation process: [VB, IN, PRP,
,, DT, NN, VBZ, .]
Our new starting nonterminals: [4, 11]
Starting and Leaf nonterminals: [2]
Overall productions found thus far: [11 -> 10 9, 10 -> 8 7, 9 -> 6 5, 8 -> VB IN,
7 -> PRP ,, 6 -> DT NN, 5 -> VBZ ., 4 -> UH 3, 3 -> , 2, 2 -> 1 0, 1 -> DT JJ,
0 -> PRP ., DT -> 'No', JJ -> 'different', PRP -> 'I', . -> '.', UH -> 'Yes',
, -> ',', VB -> 'Agree', IN -> 'with', PRP -> 'you', DT -> 'the', NN -> 'council',
VBZ -> 'does']
-------End of Algorithm-------
-------Start of Algorithm-------
Sentence: Agree with you, the council does.
All POS found in sentence: [VB, IN, PRP, ,, DT, NN, VBZ, .]
Displaying unfound nonterminals after mutation process: [11]
Our new starting nonterminals: [4, 11]
Starting and Leaf nonterminals: [2]
Overall productions found thus far: [11 -> 10 9, 10 -> 8 7, 9 -> 6 5, 8 -> VB IN,
7 -> PRP ,, 6 -> DT NN, 5 -> VBZ ., 4 -> UH 3, 3 -> , 2, 2 -> 1 0, 1 -> DT JJ,
0 -> PRP . , DT -> 'No', JJ -> 'different', PRP -> 'I', . -> '.', UH -> 'Yes',
, -> ',', VB -> 'Agree', IN -> 'with', PRP -> 'you', DT -> 'the', NN -> 'council',
VBZ -> 'does']
-------End of Algorithm-------Notice that no new S was added to “Our new starting nonterminals” array after coming across the same sentence twice. This is mutateListWithAlreadyDeclaredProductions() at work, making sure we map back to our same S, in this case, production rule ”11”.
Now that our sentences are being parsed and replaced with preexisting rules, we have to consider an edge case. Consider if a subset of S was found to be a leaf of a tree. Consider the following graph:
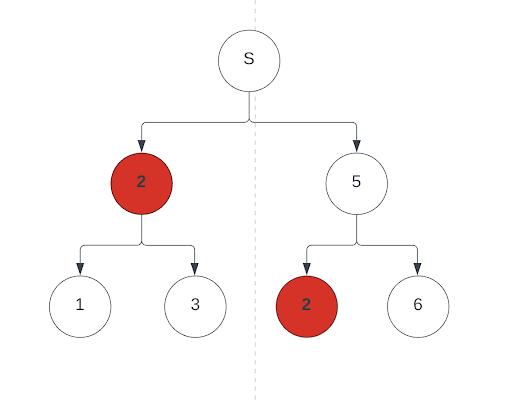
If S->2, and 2 was found to be later used in another production set, I would need to keep track of this to avoid overwriting it when updating these production rules to S later on.
Hence, determineNonterminalsThatIsChildAndStart() was created to find these. It makes it convenient to do it after mutateListWithAlreadyDeclaredProductions() as well, considering if a subset of S was found in this updated array, then it will end up being a nonterminal anyway. Here is the code used to accomplish this:
1
2
3
4
5
6
7
8
9
10
def determineNonterminalsThatIsChildAndStart(mutatedNonTerminals):
global overallStartingAndLeafNonTerminals
global overallStartingNonTerminals # Step 1
if len(mutatedNonTerminals) > 1: # Step 2
for mutatedNonTerminal in mutatedNonTerminals:
for startingNonTerminal in overallStartingNonTerminals: # Step 3
if mutatedNonTerminal == startingNonTerminal and overallStartingAndLeafNonTerminals.count(mutatedNonTerminal) == 0:
overallStartingAndLeafNonTerminals.append(startingNonTerminal)
overallStartingNonTerminals.remove(startingNonTerminal) # Step 4
- I keep track of overallProductionsFound and overallStartingNonTerminals
- Check if an existing S or one element is present, for it can’t be a leaf then
- Will loop through mutatedNonTerminals and overallStartingNonTerminals till it finds a unique match
- If the conditions are met, add this nonterminal to overallStartingAndLeafNonTerminals and remove it from overallStartingNonTerminals
This scenario is very rare in a small subset of data, but given a large corpus and examining its sentences, overallStartingAndLeafNonTerminals could end up being larger. Lets see this method in action when a subset of S is used in a sentence:
-------Start of Algorithm-------
Sentence: No different I.
All POS found in sentence: [DT, JJ, PRP, .]
Displaying unfound nonterminals after mutation process: [DT, JJ, PRP, .]
Our new starting nonterminals: [2]
Starting and Leaf nonterminals: []
Overall productions found thus far: [2 -> 1 0, 1 -> DT JJ, 0 -> PRP ., DT -> 'No',
JJ -> 'different', PRP -> 'I', . -> '.']
-------End of Algorithm-------
-------Start of Algorithm-------
Sentence: Yes, No different I.
All POS found in sentence: [UH, ,, DT, JJ, PRP, .]
Displaying unfound nonterminals after mutation process: [UH, ,, 2]
Our new starting nonterminals: [4]
Starting and Leaf nonterminals: [2]
Overall productions found thus far: [4 -> UH 3, 3 -> , 2, 2 -> 1 0, 1 -> DT JJ,
0 -> PRP ., DT -> 'No', JJ -> 'different', PRP -> 'I', . -> '.', UH -> 'Yes',
, -> ',']
-------End of Algorithm-------Here we can see the sentence “No different I.” used, but then “Yes, No Different I.” is checked using a nonterminal identified as a S candidate. Consider this visual representation:
2-> “No different I.”
Other Production Rules for Sentence…
and
4-> ”Yes, No Different I.”
4-> UH 3
3-> , 2
Other Production Rules for Sentence…
When production rule 2 is used as a subset of S and as a leaf, we will keep track of this, and print it in the statement “Starting and Leaf nonterminals: [2]”. We will eventually use this array later on when defining our S candidates, but this is an edge case to be made aware of.
Now that we are parsing a sentence with existing production rules and covering its edge cases, it’s time to map out new production rules all the way to a new S. This is what performRightToLeftProductionCreation() aims to accomplish. You’ll find that this method is rather similar in pattern to mutateListWithAlreadyDeclaredProductions(). This is something I wish to refactor it in future, as I can merge the two to accomplish both tasks based on a boolean flag of sorts. Regardless, let’s see this algorithm in action:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def performRightToLeftProductionCreation(unfoundNonTerminals):
global rollingID
global overallProductionsFound # Step 1
global overallStartingNonTerminals
index = len(unfoundNonTerminals) - 1
newNonTerminals = [] # Step 2
while index > 0:
lhs = unfoundNonTerminals.__getitem__(index - 1)
rhs = unfoundNonTerminals.__getitem__(index)
production = Production(Nonterminal(rollingID.__str__()), [lhs, rhs]) # Step 3
rollingID = rollingID + 1
overallProductionsFound.insert(0, production)
unfoundNonTerminals.pop(index)
unfoundNonTerminals.pop(index-1) # Step 4
newNonTerminals.insert(0, production.lhs())
index -= 2
if index == 0:
lhs = unfoundNonTerminals.__getitem__(index)
production = Production(Nonterminal(rollingID.__str__()), [lhs, production.lhs()])
overallProductionsFound.insert(0, production) # Step 5
unfoundNonTerminals.pop(index)
newNonTerminals.pop(index)
newNonTerminals.insert(0, production.lhs())
rollingID = rollingID + 1
if newNonTerminals.__len__() > 1:
performRightToLeftProductionCreation(newNonTerminals) # Step 6
elif newNonTerminals.__len__() != 0:
overallStartingNonTerminals.append(newNonTerminals.pop())
- Define rollingID I increment for each new production rule, overallProductionsFound, and overallStartingNonTerminals
- Begin the index at the last element and create a array called newNonTerminals to track new productions created from unfoundNonTerminals
- Loops until the index arrives at the last element. Each iteration will define a new Production rule using its lhs and rhs
- After creating this new Production rule, I track it in overallProductionsFound and take note of it in newNonTerminals
- Account for the case where we reach the end of our array to define a new Production rule as my lhs and rhs will change
- If we haven’t found our new S, perform a recursion on the method until we end up with one element in newNonTerminals. Once condition is met, add our new S in overallStartingNonTerminals
This is the final step of our process to take care of creating new production rules and also defining new S candidates based on our subset of sentences.
You can imagine after 20 sentences, the amount of interactions/iterations with elements can be quite large. Not to mention, the amount of production rules produced. In fact, we can go ahead and calculate it. Considering there are 10 words in a sentence, we end up finding/creating 19 production rules for a given sentence. If N were the amount of words in a single sentence, the amount of production rules found/produced is 2N-1. This equation is what makes Chomsky Normal Form so valuable, due to the ability to calculate computation expectations given a defined rule set. Lets see what out final set of productions is after twenty sentences:
-------Start of Algorithm-------
Sentence: There is... another... Sky... walker...
All POS found in sentence: [EX, VBZ, :, DT, :, NN, :, NN, :]
Displaying unfound nonterminals after mutation process: [EX, VBZ, :, DT, :, 75, 75]
Our new starting nonterminals: [4, 11, 17, 31, 39, 52, 57, 61, 65, 69, 73, 77, 80,
84, 90, 91, 104, 108, 119, 123, 133, 139, 142, 147, 154, 157, 158, 163, 166, 167,
168, 173, 177, 180, 181, 184, 196, 202]
Starting and Leaf nonterminals: [2]
Overall productions found thus far: [202 -> 200 201, 201 -> 198 197, 200 -> EX 199,
199 -> VBZ :, 198 -> DT :, 197 -> 75 75, 196 -> 194 195, 195 -> 193 192,
194 -> 191 189, 193 -> 188 187, 192 -> 186 185, 191 -> WRB 190, 190 -> CD CD,
189 -> NNS JJ, 188 -> PRP 23, 187 -> VBP IN, 186 -> JJ ,, 185 -> 171 155,
184 -> 183 182, 183 -> NNS VBP, 182 -> JJR ., 181 -> 161 5, 180 -> 179 178,
179 -> NNS IN, 178 -> NN 9, 177 -> 176 174, 176 -> RB 175, 175 -> JJ IN,
174 -> PRP$ 18, 173 -> 171 172, 172 -> 170 169, 171 -> PRP MD, 170 -> VB WP,
169 -> 55 85, 168 -> DT 143, 167 -> DT ., 166 -> 165 164, 165 -> DT VBZ,
164 -> WRB 134, 163 -> 161 162, 162 -> 160 159, 161 -> NNP PRP, 160 -> IN 15,
159 -> VBP 0, 158 -> NN 53, 157 -> 156 155, 156 -> NN NNS, 155 -> RB .,
154 -> 153 152, 153 -> 151 150, 152 -> 149 148, 151 -> VB CC, 150 -> VB RB,
149 -> : EX, 148 -> 35 18, 147 -> 145 146, 146 -> 144 143, 145 -> NNS RB,
144 -> VB CD, 143 -> JJ ., 142 -> 141 140, 141 -> NNP JJ, 140 -> , 18,
139 -> 137 138, 138 -> 135 134, 137 -> RB 136, 136 -> IN 34, 135 -> 8 PRP,
134 -> PRP 78, 133 -> 132 130, 132 -> 129 131, 131 -> 127 126, 130 -> 125 124,
129 -> IN 128, 128 -> IN 6, 127 -> NNS PRP, 126 -> 23 RB, 125 -> NN MD,
124 -> PRP 12, 123 -> 122 120, 122 -> 6 121, 121 -> IN 36, 120 -> 34 37,
119 -> 117 118, 118 -> 116 115, 117 -> 114 113, 116 -> 112 111, 115 -> 110 109,
114 -> 6 PRP, 113 -> VBD ,, 112 -> VBN PRP, 111 -> VBZ ,, 110 -> VBN IN,
109 -> NNP 32, 108 -> 107 105, 107 -> VBN 106, 106 -> 87 NNP, 105 -> JJ 89,
104 -> 102 103, 103 -> 100 99, 102 -> 98 101, 101 -> 97 96, 100 -> 95 94,
99 -> 93 92, 98 -> JJ 45, 97 -> PRP RB, 96 -> VBP :, 95 -> PRP$ JJ, 94 -> 75 DT,
93 -> VBZ RB, 92 -> DT 18, 91 -> 87 70, 90 -> 88 89, 89 -> 86 85, 88 -> 6 87,
87 -> IN 33, 86 -> NNP VBZ, 85 -> VBN ., 84 -> 83 81, 83 -> NNP 82,
82 -> NNP ,, 81 -> RB 18, 80 -> 79 78, 79 -> 14 PRP, 78 -> VBP ., 77 -> 76 74,
76 -> WRB 75, 75 -> NN :, 74 -> WRB 18, 73 -> 72 70, 72 -> VBN 71, 71 -> 6 NNP,
70 -> NNP 5, 69 -> 68 66, 68 -> IN 67, 67 -> DT NNS, 66 -> 6 18, 65 -> 64 62,
64 -> RB 63, 63 -> JJ 6, 62 -> IN 9, 61 -> 60 58, 60 -> NNP 59, 59 -> POS NN,
58 -> 55 53, 57 -> 55 56, 56 -> 54 53, 55 -> PRP VBP, 54 -> JJ NN, 53 -> IN 0,
52 -> 50 51, 51 -> 48 47, 50 -> 46 49, 49 -> 45 44, 48 -> 43 42, 47 -> 41 40,
46 -> NN VBZ, 45 -> TO VB, 44 -> , JJR, 43 -> VBZ TO, 42 -> VB :, 41 -> VB NNS,
40 -> TO 18, 39 -> 38 37, 38 -> 36 34, 37 -> 33 32, 36 -> NN 35, 35 -> VBZ DT,
34 -> NN TO, 33 -> DT NNP, 32 -> NNP ., 31 -> 29 30, 30 -> 27 26, 29 -> 25 28,
28 -> 23 22, 27 -> 21 20, 26 -> 19 18, 25 -> RB 24, 24 -> CD EX, 23 -> VBP ,,
22 -> DT JJR, 21 -> , 6, 20 -> : 6, 19 -> CC DT, 18 -> NN ., 17 -> 15 16,
16 -> 13 12, 15 -> PRP$ 14, 14 -> NN ,, 13 -> NNP MD, 12 -> VB ., 11 -> 10 9,
10 -> 8 7, 9 -> 6 5, 8 -> VB IN, 7 -> PRP ,, 6 -> DT NN, 5 -> VBZ ., 4 -> UH 3,
3 -> , 2, 2 -> 1 0, 1 -> DT JJ, 0 -> PRP ., DT -> 'No', JJ -> 'different',
PRP -> 'I', . -> '.', UH -> 'Yes', , -> ',', VB -> 'Agree', IN -> 'with',
PRP -> 'you', DT -> 'the', NN -> 'council', VBZ -> 'does', PRP$ -> 'Your',
NN -> 'apprentice', NNP -> 'Skywalker', MD -> 'will', VB -> 'be', RB -> 'Always',
CD -> 'two', EX -> 'there', VBP -> 'are', DT -> 'no', JJR -> 'more',
NN -> 'less', : -> ':', DT -> 'a', NN -> 'master', CC -> 'and', DT -> 'an',
NN -> 'Fear', VBZ -> 'is', NN -> 'path', TO -> 'to', NNP -> 'Dark', NNP -> 'Side',
VBZ -> 'leads', VB -> 'anger', JJR -> 'anger', VB -> 'hate', : -> ';',
NNS -> 'leads', NN -> 'suffering', VBP -> 'sense', JJ -> 'much', NN -> 'fear',
IN -> 'in', NNP -> 'Qui-Gon', POS -> "'s", NN -> 'defiance', RB -> 'Truly',
JJ -> 'wonderful', NN -> 'mind', IN -> 'of', NN -> 'child', IN -> 'Around',
NNS -> 'survivors', NN -> 'perimeter', NN -> 'create', VBN -> 'Lost',
NN -> 'planet', NNP -> 'Master', NNP -> 'Obi-Wan', VBZ -> 'has', WRB -> 'How',
NN -> 'embarrassing',: -> '...', NN -> 'Victory', VBP -> 'say', . -> '?',
RB -> 'not', NN -> 'victory', DT -> 'The', NN -> 'shroud', VBN -> 'fallen',
IN -> 'Begun', NNP -> 'Clone', NNP -> 'War', JJ -> 'Much', VB -> 'learn',
RB -> 'still', VBP -> 'have', PRP$ -> 'my', JJ -> 'old', NN -> 'padawan',
DT -> 'this', RB -> 'just', NN -> 'beginning', . -> '!', VBN -> 'Twisted',
IN -> 'by', JJ -> 'young', VBN -> 'become',
NN -> 'boy', VBD -> 'trained', VBN -> 'gone',
PRP -> 'he', VBN -> 'consumed', NNP -> 'Darth', NNP -> 'Vader', NN -> 'loss',
IN -> 'If', IN -> 'into', NN -> 'security',
NNS -> 'recordings', VBP -> 'go', RB -> 'only',
NN -> 'pain', VB -> 'find', RB -> 'Not',
IN -> 'if', NN -> 'anything', VB -> 'say',
IN -> 'about', PRP -> 'it', NNP -> 'Great',
JJ -> 'warrior', NN -> 'hmm', NNS -> 'Wars',
VB -> 'make', CD -> 'one', JJ -> 'great',
VB -> 'Do', CC -> 'or', VB -> 'do', NN -> 'try',
NN -> 'Size', NNS -> 'matters', NN -> 'Look',
IN -> 'at', PRP -> 'me', NNP -> 'Judge',
NN -> 'size', VBP -> 'do', DT -> 'That',
WRB -> 'why', VBP -> 'fail', JJ -> 'similar',
PRP -> 'You', MD -> 'must', VB -> 'unlearn',
WP -> 'what', VBN -> 'learned', RB -> 'Only',
PRP$ -> 'your', NNS -> 'Always',
NN -> 'motion', NN -> 'future', NNP -> 'Reckless',
NNS -> 'Matters', JJR -> 'worse', WRB -> 'When', CD -> 'nine', CD -> 'hundred',
NNS -> 'years', VBP -> 'reach', VBP -> 'look',
IN -> 'as', JJ -> 'good', EX -> 'There',
DT -> 'another', NN -> 'Sky', NN -> 'walker']
-------End of Algorithm-------Wow, that is a lot of production rules! Not to mention, a lot of starting nonterminals identified! I’m sure if we mapped this entire set into a visible tree, we would not only have a huge tree to look at, but be able to reproduce all sentences found in our array by starting with a given S!
At this point, I wanted to play around with my new CFG and generate some random sentences. But before I do this, I have to: define which production rules make up S, use NLTK CFG class to map these rules for further use, and then finally generate some random yoda sentences! Lets see this final piece in action:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
for startingNonTerminal in overallStartingNonTerminals:
for production in overallProductionsFound:
if(production.lhs() == startingNonTerminal):
overallProductionsFound.append(Production(Nonterminal("S"), production.rhs())) # Step 1
overallProductionsFound.remove(production)
for startingAndLeadNonTerminal in overallStartingAndLeafNonTerminals:
for production in overallProductionsFound:
if(production.lhs() == startingAndLeadNonTerminal): # Step 2
overallProductionsFound.append(Production(Nonterminal("S"), production.rhs()))
print("New productions found after adding S: " + overallProductionsFound.__str__())
customCFG = CFG(Nonterminal("S"), overallProductionsFound) # Step 3
print("Is this in chomsky normal form: " + customCFG.is_chomsky_normal_form().__str__())
print("------------------------------------------------------------------------------------------------------------------------")
for sentence in quotes:
print("Sentence: " + sentence)
sent = word_tokenize(sentence)
parser = nltk.ChartParser(customCFG) # Step 4
trees = list(parser.parse(sent))
print("Tree: " + trees.__str__())
#print("------------------------------------------------------------------------------------------------------------------------")
#count=0
#for sentences in generate(customCFG):
# if(count%10000000 == 0): # Step 5
# print(' '.join(sentences))
# count+=1
- Replace Productions lhs() to what we found to be S in overallStartingNonTerminals
- Append Production elements for S values that are in overallStartingAndLeafNonTerminals (Keeps original S rule intact)
- Use NLTK CFG class to have a central class that stores our rules
- Print one-liner print statements for N sentences to demonstrate how sentences are being mapped in our CFG using parser.parse()
- Commented out for a reason. These lines use NLTK tool generate() to craft random sentences based off our CFG
Steps one and two were certainly mistakes made when looking at constructing a CFG class. I assumed CFG constructor needed an array of starting Nonterminal(s), but it turns out it needed one Nonterminal as an identifier. Hence, I went ahead and added the S in overallProductionsFound through a looping mechanism. I could have added this as a step in previous methods, but avoided it to maintain working changes (This is why Test Driven Development is important as it helps drive and maintain your design! I intended to add tests before making a solution, but my Hackathon instincts kicked in. Will be more careful next time.)
Lets see how step four displays our sentences being mapped out by our CFG:
Sentence: No different I.
Tree: [Tree('S', [Tree('1', [
Tree('DT', ['No']), Tree('JJ', ['different'])]), Tree('0', [
Tree('PRP', ['I']), Tree('.', ['.'])])])]
Sentence: Yes, No different I.
Tree: [Tree('S', [Tree('UH', ['Yes']), Tree('3', [
Tree(',', [',']), Tree('2', [Tree('
1', [Tree('DT', ['No']), Tree('JJ', ['different'])]), Tree('0', [Tree('PRP', ['I'])
, Tree('.', ['.'])])])])])]
Sentence: Agree with you, the council does.
Tree:[Tree('S', [Tree('10', [Tree('
8', [Tree('VB', ['Agree']), Tree('
IN', ['with'])]), Tree('7', [Tree('PRP', ['you']), Tree(',', [','])])]), Tree('
9', [Tree('6', [Tree('DT', ['the']), Tree('NN', ['council'])]), Tree('5', [Tree('
VBZ', ['does']), Tree('.', ['.'])])])])]
Sentence: Agree with you, the council does.
Tree: [Tree('S', [Tree('10', [Tree('
8', [Tree('VB', ['Agree']), Tree('
IN', ['with'])]), Tree('7', [Tree('PRP', ['you']), Tree(',', [','])])]), Tree('
9', [Tree('6', [Tree('DT', ['the']), Tree('NN', ['council'])]), Tree('5', [Tree('
VBZ', ['does']), Tree('.', ['.'])])])])]
Sentence: Your apprentice, Skywalker will be.
Tree: [Tree('S', [Tree('15', [Tree('
PRP$', ['Your']), Tree('14', [Tree('
NN', ['apprentice']), Tree(',', [','])])]), Tree('16', [Tree('13', [Tree('
NNP', ['Skywalker']), Tree('MD', ['will'])]), Tree('12', [Tree('VB', ['be']),
Tree('.', ['.'])])])])]
Sentence: Always two there are, no more, no less: a master and an apprentice.
Tree: [Tree('S', [Tree('29', [Tree('25', [
Tree('RB', ['Always']), Tree('24', [Tree('CD', ['two']), Tree('EX', ['there'])])]),
Tree('28', [Tree('23', [Tree('
VBP', ['are']), Tree(',', [','])]), Tree('22', [Tree('DT', ['no']), Tree('
JJR', ['more'])])])]), Tree('30', [Tree('
27', [Tree('21', [Tree(',', [',']), Tree('6', [Tree('DT', ['no']), Tree('
NN', ['less'])])]), Tree('20', [Tree(':'
, [':']), Tree('6', [Tree('DT', ['a']), Tree('NN', ['master'])])])]), Tree('26', [
Tree('19', [Tree('CC', ['and']), Tree('DT', ['an'])]), Tree('18', [Tree('
NN', ['apprentice']), Tree('.', ['.'])])])])])]
Sentence: Fear is the path to the Dark Side.
Tree: [Tree('S', [Tree('38', [Tree('
36', [Tree('NN', ['Fear']), Tree('
35', [Tree('VBZ', ['is']), Tree('DT', ['the'])])]), Tree('34', [Tree('
NN', ['path']), Tree('TO', ['to'])])]), Tree('
37', [Tree('33', [Tree('DT', ['the']), Tree('NNP', ['Dark'])]), Tree('32', [Tree('
NNP', ['Side']), Tree('
.', ['.'])])])])]
Sentence: Fear leads to anger, anger leads to hate; hate leads to suffering.
Tree: [Tree('S', [Tree('50', [Tree('46', [
Tree('NN', ['Fear']), Tree('VBZ', ['leads'])]), Tree('49', [Tree('45', [Tree('
TO', ['to']), Tree('VB', ['anger'])]), Tree('44', [Tree(',', [',']), Tree('
JJR', ['anger'])])])]), Tree('51', [Tree('48', [Tree('43', [Tree('VBZ', ['leads']),
Tree('TO', ['to'])]), Tree('42', [Tree('VB', ['hate']), Tree(':', [';'])])]),
Tree('47', [Tree('41', [Tree('
VB', ['hate']), Tree('NNS', ['leads'])]), Tree('40', [Tree('TO', ['to']), Tree('
18', [Tree('NN', ['suffering']), Tree('
.', ['.'])])])])])])]
Sentence: I sense much fear in you.
Tree: [Tree('S', [Tree('55', [Tree('
PRP', ['I']), Tree('VBP', ['sense'])]), Tree('
56', [Tree('54', [Tree('JJ', ['much']), Tree('NN', ['fear'])]), Tree('53', [Tree('
IN', ['in']), Tree('0', [Tree('
PRP', ['you']), Tree('.', ['.'])])])])])]
Sentence: Qui-Gon's defiance I sense in you.
Tree: [Tree('S', [Tree('60', [Tree('
NNP', ['Qui-Gon']), Tree('59', [Tree('
POS', ["'s"]), Tree('NN', ['defiance'])])]), Tree('58', [Tree('55', [Tree('
PRP', ['I']), Tree('VBP', ['sense'])]), Tree('53', [Tree('IN', ['in']), Tree('0', [
Tree('PRP', ['you']), Tree('.', ['.'])])])])])]
Sentence: Truly wonderful the mind of a child is.
Tree: [Tree('S', [Tree('64', [
Tree('RB', ['Truly']), Tree('63', [
Tree('JJ', ['wonderful']), Tree('6', [Tree('DT', ['the']), Tree('
NN', ['mind'])])])]), Tree('62', [Tree('IN', ['of']), Tree('9', [Tree('6', [Tree('
DT', ['a']), Tree('NN', ['child'])]), Tree('5', [Tree('VBZ', ['is']), Tree('
.', ['.'])])])])])]
Sentence: Around the survivors a perimeter create.
Tree: [Tree('S', [Tree('68', [
Tree('IN', ['Around']), Tree('67', [
Tree('DT', ['the']), Tree('NNS', ['survivors'])])]), Tree('66', [Tree('6', [Tree('
DT', ['a']), Tree('
NN', ['perimeter'])]), Tree('18', [Tree('NN', ['create']), Tree('.', ['.'])])])])]
Sentence: Lost a planet Master Obi-Wan has.
Tree: [Tree('S', [Tree('72', [Tree('
VBN', ['Lost']), Tree('71', [Tree('6', [
Tree('DT', ['a']), Tree('NN', ['planet'])]), Tree('NNP', ['Master'])])]), Tree('
70', [Tree('NNP', ['Obi-Wan']), Tree('
5', [Tree('VBZ', ['has']), Tree('.', ['.'])])])])]
Sentence: How embarrassing...How embarrassing.
Tree: [Tree('S', [Tree('76', [Tree('
WRB', ['How']), Tree('75', [Tree('
NN', ['embarrassing']), Tree(':', ['...'])])]), Tree('74', [Tree('WRB', ['How']),
Tree('18', [Tree('
NN', ['embarrassing']), Tree('.', ['.'])])])])]
Sentence: Victory, you say?
Tree: [Tree('S', [Tree('79', [Tree('14', [Tree('
NN', ['Victory']), Tree(',', [','])]), Tree('PRP', ['you'])]), Tree('78', [Tree('
VBP', ['say']), Tree('.', ['?'])])])]
Sentence: Master Obi-Wan, not victory.
Tree: [Tree('S', [Tree('83', [Tree('
NNP', ['Master']), Tree('82', [Tree('
NNP', ['Obi-Wan']), Tree(',', [','])])]), Tree('81', [Tree('RB', ['not']), Tree('
18', [Tree('NN', ['victory']), Tree('
.', ['.'])])])])]
Sentence: The shroud of the Dark Side has fallen.
Tree: [Tree('S', [Tree('88', [
Tree('6', [Tree('DT', ['The']), Tree('
NN', ['shroud'])]), Tree('87', [Tree('IN', ['of']), Tree('33', [Tree('DT', ['the'])
, Tree('NNP', ['Dark'])])])]), Tree('
89', [Tree('86', [Tree('NNP', ['Side']), Tree('VBZ', ['has'])]), Tree('85', [Tree('
VBN', ['fallen']), Tree('
.', ['.'])])])])]
Sentence: Begun the Clone War has.
Tree: [Tree('S', [Tree('87', [Tree('
IN', ['Begun']), Tree('33', [Tree('DT', ['the']), Tree('NNP', ['Clone'])])]),
Tree('70', [Tree('NNP', ['War']), Tree('5', [Tree('VBZ', ['has']), Tree('
.', ['.'])])])])]
Sentence: Much to learn you still have... my old padawan... this is just the
beginning!
Tree: [Tree('S', [Tree('102', [Tree('98', [Tree('JJ', ['Much']), Tree('45', [Tree('
TO', ['to']), Tree('
VB', ['learn'])])]), Tree('101', [Tree('97', [Tree('PRP', ['you']), Tree('
RB', ['still'])]), Tree('96', [Tree('
VBP', ['have']), Tree(':', ['...'])])])]), Tree('103', [Tree('100', [Tree('95', [
Tree('PRP$', ['my']), Tree('
JJ', ['old'])]), Tree('94', [Tree('75', [Tree('NN', ['padawan']), Tree(':'
, ['...'])]), Tree('DT', ['this'])])]), Tree('
99', [Tree('93', [Tree('VBZ', ['is']), Tree('RB', ['just'])]), Tree('92', [Tree('
DT', ['the']), Tree('18', [Tree('
NN', ['beginning']), Tree('.', ['!'])])])])])])]
Sentence: Twisted by the Dark Side young Skywalker has become.
Tree: [Tree('S', [
Tree('107', [Tree('VBN', ['Twisted']), Tree('106', [Tree('87', [Tree('IN', ['by']),
Tree('33', [Tree('DT', ['the']), Tree('NNP', ['Dark'])])]), Tree('
NNP', ['Side'])])]), Tree('105', [Tree('JJ', ['young']), Tree('89', [Tree('86', [
Tree('NNP', ['Skywalker']), Tree('
VBZ', ['has'])]), Tree('85', [Tree('VBN', ['become']), Tree('.', ['.'])])])])])]
Sentence: The boy you trained, gone he is, consumed by Darth Vader.
Tree: [Tree('
S', [Tree('117', [Tree('114', [Tree('
6', [Tree('DT', ['The']), Tree('NN', ['boy'])]), Tree('PRP', ['you'])]), Tree('
113', [Tree('VBD', ['trained']), Tree('
,', [','])])]), Tree('118', [Tree('116', [Tree('112', [Tree('VBN', ['gone']),
Tree('PRP', ['he'])]), Tree('111', [Tree('
VBZ', ['is']), Tree(',', [','])])]), Tree('115', [Tree('110', [Tree('
VBN', ['consumed']), Tree('IN', ['by'])]), Tree('
109', [Tree('NNP', ['Darth']), Tree('32', [Tree('NNP', ['Vader']), Tree('
.', ['.'])])])])])])]
Sentence: The fear of loss is a path to the Dark Side.
Tree: [Tree('S', [Tree('
122', [Tree('6', [Tree('DT', ['The']), Tree('NN', ['fear'])]), Tree('121', [Tree('
IN', ['of']), Tree('36', [Tree('NN', ['loss']), Tree('35', [Tree('
VBZ', ['is']), Tree('DT', ['a'])])])])]), Tree('120', [Tree('34', [Tree('
NN', ['path']), Tree('TO', ['to'])]), Tree('
37', [Tree('33', [Tree('DT', ['the']), Tree('NNP', ['Dark'])]), Tree('32', [Tree('
NNP', ['Side']), Tree('
.', ['.'])])])])])]
Sentence: If into the security recordings you go, only pain will you find.
Tree: [
Tree('S', [Tree('132', [Tree('129', [
Tree('IN', ['If']), Tree('128', [Tree('IN', ['into']), Tree('6', [Tree('
DT', ['the']), Tree('NN', ['security'])])])]), Tree('131', [Tree('127', [Tree('
NNS', ['recordings']), Tree('PRP', ['you'])]), Tree('126', [Tree('23', [Tree('
VBP', ['go']), Tree(',', [','])]), Tree('RB', ['only'])])])]), Tree('130', [Tree('
125', [Tree('NN', ['pain']), Tree('
MD', ['will'])]), Tree('124', [Tree('PRP', ['you']), Tree('12', [Tree('
VB', ['find']), Tree('.', ['.'])])])])])]
Sentence: Not if anything to say about it I have.
Tree: [Tree('S', [Tree('137', [
Tree('RB', ['Not']), Tree('136', [
Tree('IN', ['if']), Tree('34', [Tree('NN', ['anything']), Tree('TO', ['to'])])])]),
Tree('138', [Tree('135', [Tree('
8', [Tree('VB', ['say']), Tree('IN', ['about'])]), Tree('PRP', ['it'])]), Tree('
134', [Tree('PRP', ['I']), Tree('78', [
Tree('VBP', ['have']), Tree('.', ['.'])])])])])]
Sentence: Great warrior, hmm?
Tree: [Tree('S', [Tree('141', [Tree('NNP', ['Great'])
, Tree('JJ', ['warrior'])]), Tree('
140', [Tree(',', [',']), Tree('18', [Tree('NN', ['hmm']), Tree('.', ['?'])])])])]
Sentence: Wars not make one great.
Tree: [Tree('S', [Tree('145', [Tree('
NNS', ['Wars']), Tree('RB', ['not'])]), Tree('
146', [Tree('144', [Tree('VB', ['make']), Tree('CD', ['one'])]), Tree('143', [
Tree('JJ', ['great']), Tree('
.', ['.'])])])])]
Sentence: Do or do not; there is no try.
Tree: [Tree('S', [Tree('153', [Tree('
151', [Tree('VB', ['Do']), Tree('
CC', ['or'])]), Tree('150', [Tree('VB', ['do']), Tree('RB', ['not'])])]), Tree('
152', [Tree('149', [Tree(':', [';']), Tree('EX', ['there'])]), Tree('148', [Tree('
35', [Tree('VBZ', ['is']), Tree('DT', ['no'])]), Tree('18', [Tree('
NN', ['try']), Tree('.', ['.'])])])])])]
Sentence: Size matters not.
Tree: [Tree('S', [Tree('156', [Tree('NN', ['Size']),
Tree('NNS', ['matters'])]), Tree('
155', [Tree('RB', ['not']), Tree('.', ['.'])])])]
Sentence: Look at me.
Tree: [Tree('S', [Tree('NN', ['Look']), Tree('53', [Tree('
IN', ['at']), Tree('0', [Tree('
PRP', ['me']), Tree('.', ['.'])])])])]
Sentence: Judge me by my size, do you?
Tree: [Tree('S', [Tree('161', [Tree('
NNP', ['Judge']), Tree('PRP', ['me'])]), Tree('162', [Tree('160', [Tree('
IN', ['by']), Tree('15', [Tree('PRP$', ['my']), Tree('14', [Tree('NN', ['size']),
Tree(',', [','])])])]), Tree('159', [Tree('VBP', ['do']),
Tree('0', [Tree('PRP', ['you']), Tree('.', ['?'])])])])])]
Sentence: That is why you fail.
Tree: [Tree('S', [Tree('165', [Tree('DT', ['That'])
, Tree('VBZ', ['is'])]), Tree('
164', [Tree('WRB', ['why']), Tree('134', [Tree('PRP', ['you']), Tree('78', [Tree('
VBP', ['fail']), Tree('
.', ['.'])])])])])]
Sentence: No!
Tree: [Tree('S', [Tree('DT', ['No']), Tree('.', ['!'])])]
Sentence: No similar.
Tree: [Tree('S', [Tree('DT', ['No']), Tree('143', [Tree('
JJ', ['similar']), Tree('.', ['.'])])])]
Sentence: You must unlearn what you have learned.
Tree: [Tree('S', [Tree('171', [
Tree('PRP', ['You']), Tree('
MD', ['must'])]), Tree('172', [Tree('170', [Tree('VB', ['unlearn']), Tree('
WP', ['what'])]), Tree('169', [Tree('55', [
Tree('PRP', ['you']), Tree('VBP', ['have'])]), Tree('85', [Tree('VBN', ['learned'])
, Tree('.', ['.'])])])])])]
Sentence: Only different in your mind.
Tree: [Tree('S', [Tree('176', [Tree('
RB', ['Only']), Tree('175', [Tree('
JJ', ['different']), Tree('IN', ['in'])])]), Tree('174', [Tree('PRP$', ['your']),
Tree('18', [Tree('NN', ['mind']), Tree('.', ['.'])])])])]
Sentence: Always in motion the future is.
Tree: [Tree('S', [Tree('179', [Tree('
NNS', ['Always']), Tree('IN', ['in'])]), Tree('178', [Tree('NN', ['motion']),
Tree('9', [Tree('6', [Tree('DT', ['the']), Tree('NN', ['future'])]), Tree('5', [
Tree('VBZ', ['is']), Tree('.', ['.'])])])])])]
Sentence: Reckless he is.
Tree: [Tree('S', [Tree('161', [Tree('NNP', ['Reckless']),
Tree('PRP', ['he'])]), Tree('5', [
Tree('VBZ', ['is']), Tree('.', ['.'])])])]
Sentence: Matters are worse.
Tree: [Tree('S', [Tree('183', [Tree('
NNS', ['Matters']), Tree('VBP', ['are'])]), Tree('
182', [Tree('JJR', ['worse']), Tree('.', ['.'])])])]
Sentence: When nine hundred years old you reach, look as good, you will not.
Tree: [Tree('S', [Tree('194', [Tree('
191', [Tree('WRB', ['When']), Tree('190', [Tree('CD', ['nine']), Tree('
CD', ['hundred'])])]), Tree('189', [Tree('
NNS', ['years']), Tree('JJ', ['old'])])]), Tree('195', [Tree('193', [Tree('188', [
Tree('PRP', ['you']), Tree('23', [
Tree('VBP', ['reach']), Tree(',', [','])])]), Tree('187', [Tree('VBP', ['look']),
Tree('IN', ['as'])])]), Tree('192', [
Tree('186', [Tree('JJ', ['good']), Tree(',', [','])]), Tree('185', [Tree('171', [
Tree('PRP', ['you']), Tree('
MD', ['will'])]), Tree('155', [Tree('RB', ['not']), Tree('.', ['.'])])])])])])]
Sentence: No.
Tree: [Tree('S', [Tree('DT', ['No']), Tree('.', ['.'])])]
Sentence: There is... another... Sky... walker...
Tree: [Tree('S', [Tree('200', [
Tree('EX', ['There']), Tree('199', [
Tree('VBZ', ['is']), Tree(':', ['...'])])]), Tree('201', [Tree('198', [Tree('
DT', ['another']), Tree(':', ['...'])]), Tree('197', [Tree('75', [Tree('
NN', ['Sky']), Tree(':', ['...'])]), Tree('75', [Tree('NN', ['walker']), Tree(':'
, ['...'])])])])])]So what are we looking at here? Let’s take the sentence “I sense much fear in you.” as an example. It maps out as:
[Tree('S', [Tree('55', [Tree('PRP', ['I']), Tree('VBP', ['sense'])]), Tree('56',
[Tree('54', [Tree('JJ', ['much']), Tree('NN', ['fear'])]),
Tree('53', [Tree('IN', ['in']), Tree('0', [Tree('PRP', ['you']),
Tree('.', ['.'])])])])])]Remember, S is the starting nonterminal and will be mapped out by a set of productions. Here S, envelopes the entire sentence, and its production rules eventually map out to its terminals. Lets translate the above now to a diagram:
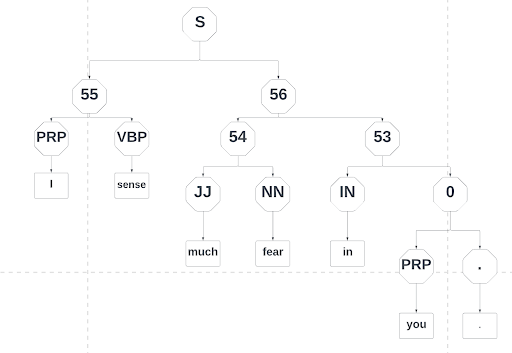
That’s right, if we were to perform a Depth-First search algorithm with this tree, we would be able to reproduce our sentence. Notice that the algorithm does its best to evenly distribute productions on the left and right side of S. This is why I parsed and produced new Production(s) with a skip over of two elements (index-=2). I wanted a tree that wasn’t too left oriented nor right oriented. Instead, I wanted to make sentences as evenly distributed as possible within the confines Chomsky Normal Form.
Now that we know our sentences are being parsed back properly (remember S->T and T->S), let’s start generating sentences. NLTK provides the tools to generate sentences with your CFG given you provided terminal values or “A->a”. I did some research on how to provide random words vs what I provided in a given sentence, but couldn’t come to a reasonable solution (Maybe something to explore in the future!) Lets see how step five generates a huge list of random sentences:
Yes , No different I .
Always two there are , No more , No Fear : an suffering and the perimeter ?
Always two there are , No more , No child : no create or a padawan !
Always two there are , No more , No victory : No beginning and The try .
Always two there are , No more , No loss ... That hmm or That walker ?
Always two there are , No more , No Size ... The Sky or the suffering !
Always two there are , No more , No walker ... an path and a embarrassing .
Always two there are , No more , the path ... no perimeter or The loss ?
Always two there are , No more , the perimeter ... No padawan and That Look !
Always two there are , No more , the shroud ; That hmm and the less .
Always two there are , No more , the pain ; The future or a mind ?
Always two there are , No more , the size ; an Fear and The victory !
Always two there are , No more , no apprentice ; no child or That anything .
Always two there are , No more , no fear ; No shroud or No future ?
Always two there are , No more , no planet : That anything and a Fear !
Always two there are , No more , no beginning : The motion or The create .
Always two there are , No more , no hmm : an master and That beginning ?
Always two there are , No more , no future : no child and No try !
Always two there are , No more , a master : No victory or a council .
Always two there are , No more , a defiance ... That pain and The fear ?I had to wrap my generate() loop with a modulus of million to get a clean output as it would generate a multitude of sentences. The above shows the structure of the sentence “Always two there are, no more, no less: a master and an apprentice.” often with variations made to the right side. This is due to the multitude of options available within the given S as we have made available multiple terminals/words with multiple POS to cover. The method generate() alone would try to generate every possible combination, creating an observable infinite reproduction of sentences.
Not only that, but we can clearly see that these sentences do not make much sense. They truly are riddles, which fits the persona of Yoda in the end. If we wanted to see sentences that have more weight and meaning, we would have to dive into the statistics of a probable CFG for each route available (Something to explore later on!).
Regardless, we can clearly see the value and problems with a CFG with an Chomsky Normal Form approach. It does a great job at defining the structure and rules to reproduce a sentence, but is terrible when it comes to generating meaningful sentences based on its model. The uses for this could vary from case to case. One possible use is to study unique languages and its POS to help identify possible responses. Another is to identify the use of a word based on what POS it is paired with given a set of sentences. Another keynote to take away is this model can be generated dynamically without interference, but has no mechanism to learn over time on what an appropriate sentence looks like.
Checkpoint
In this post, we went over some great figures in the NLP world, roads of thought for a NLP solution, how these roads of thought map to the modern day world, and a coding challenge for CFG for a subset of sentences. The coding problem certainly took some time and research, but boy was it worth it. Seeing this tree being used to generate random sentences of any caliber is exciting enough, especially researching ways on how it can be improved in all ways, shapes, and forms. I definitely want to revisit this code and further improve upon it when the time comes. But for now, I believe the point is made. CFGs with no statistics applied to your NLP solutions will produce cryptic messages, but may fit some solutions.
References
Foundations of Statistical Natural Language Processing, 1st Edition
Wittgenste in Philosophy of Language
Colorless Green Ideas Sleep Furiously Topic
Good Slides on Chomsky Normal Form
Future of Computational Linguistics Paper
More coding references are provided in README.md in git repo Here